astronomia_rag
A modular retrieval-augmented FAQ for observational astronomy. A 15-file Portuguese corpus is chunked, embedded, and served through a history-aware retriever over Mistral-7B (Ollama), answering domain questions with grounded, citable context.
overview
The system takes a natural-language question, retrieves the most relevant passages from an astronomy corpus, and feeds them as context to a language model that generates the answer. This pattern introduced by Lewis et al. (2020) under the name Retrieval-Augmented Generation, addresses two chronic LLM problems: outdated knowledge and the tendency to hallucinate when relying solely on parametric memory.
Three traits set this implementation apart from a tutorial-grade RAG:
- Runs 100% locally, with no API costs, using an open-source model (Mistral 7B) served by Ollama
- Refuses out-of-domain questions instead of making up answers
- Is quantitatively evaluated with a retrieval metric and a failure analysis.
Note: the corpus and the chatbot’s answers are in Brazilian Portuguese, but the pipeline itself is language-agnostic; the embedding model’s bias toward English is one of the findings discussed ahead.
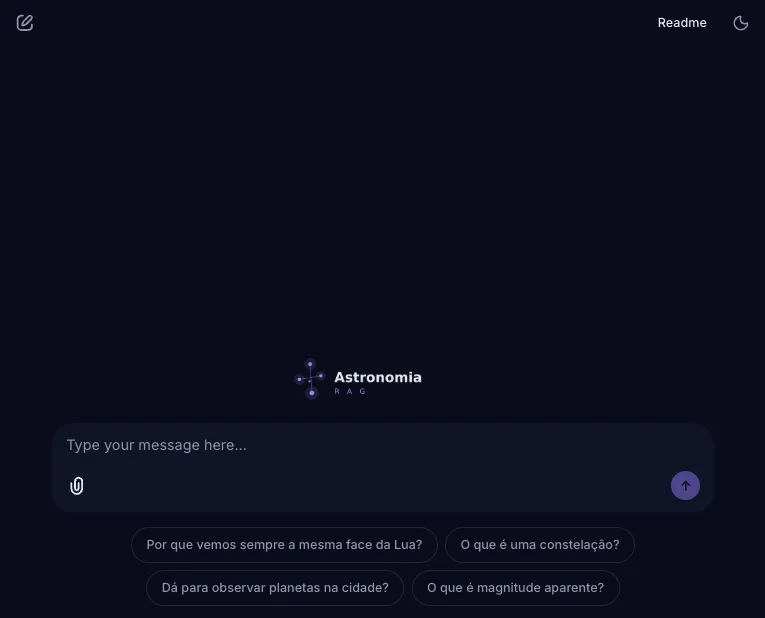
What it does
Section titled “What it does”The pipeline ingests a curated Portuguese corpus on observational astronomy, splits it into overlapping chunks, and indexes them with sentence-transformer embeddings in a FAISS vector store. At query time, a history-aware retriever reformulates the question against the conversation, pulls the top-k passages, and conditions Mistral-7B on them via a LangChain LCEL chain.
- Fully modular: ingestion, embedding, retrieval, and generation are swappable components.
- Evaluated against a 30-question golden set with both retrieval and subjective-quality metrics.
- Reusable architecture — the same engine backs the SPACE astronomy almanac corpus.
architecture
The system consists of two flows: offline (run once) and querying (online, per question).
During indexing, the corpus is split into chunks, each chunk is turned into a vector by an embedding model, and the vectors are stored in a FAISS index persisted to disk. During querying, the question goes through the same embedder, the nearest vectors are searched in FAISS, and the retrieved chunks (together with the conversation history), form the context handed to Mistral-7B, which generates the answer.
Pipeline
Section titled “Pipeline”methodology
Tech Stack
Section titled “Tech Stack”| Layer | Technology | Description |
| Embeddings | `all-MiniLM-L6-v2` | Lightweight (384 dimensions), runs on CPU. Belong to the Sentence-BERT family (Relmers & Gurevych, 2019) |
| Vector Store | FAISS | Efficient similarity search (Johnson *et al.*, 2029) |
| LLM | Mistral-7B-Instruct (via Ollama) | Open model (Jiang *et al.*, 2023); runs locally, no API costs |
| Orchestration | LangChain | Composes the pipeline with standardized components |
| Interface | CLI and Chainlit | CLI for command-line usage, Chainlit for a more user-friendly experience |
How RAG works
Section titled “How RAG works”Without retrieval, an LLM answers only from the parametric knowledge it encapsulated during training, and when it doesn’t know, it tends to fabricate. RAG (Lewis et al., 2020) changes the flow:
- Index the external knowledge (corpus) into a vector store
- Retrieve the most relevant passages for each question
- Augment the LLM’s prompt with those passages as context
- Generate the answer grounded in the context.
Implementation
Section titled “Implementation”1. Corpus
Section titled “1. Corpus”15 documents in Brazilian Portuguese (~4,600 words) covering the Solar System, the Moon, constellations, stars, galaxies, black holes, telescopes, eclipses, meteor showers, magnitude, celestial coordinates, amateur astronomy, urban observing, history and cosmology.
2. Chunking
Section titled “2. Chunking”Documents are split with RecursiveCharacterTextSplitter(500 characters, 50 overlap), which tries to break first on paragraphs, then sentences and words. The corpus produced 86 chunks. The overlap preserves context that falls on the boundary between two chunks.
3. Embeddings and Indexing
Section titled “3. Embeddings and Indexing”Each chunk becomes a 384-dimensional vector via all-MiniLM-L6-v2. This model belongs to the Sentence-BERT family (Reimers & Gurevych, 2019), which produces sentence-level embeddings whose cosine similarity reflects semantic similarity, a prerequisite for meaningful vector search. Vectors are normalized (making cosine similarity equivalent to the inner product) and indexed in FAISS (Johnson et al., 2019).
4. Retrieval
Section titled “4. Retrieval”For each question, the three most similar chunks are retrieved (top-k = 3). Retrieving by vector similarity rather than keyword overlap is the dense retrieval paradigm (Karpukhin et al., 2020), which represents queries and passages in a shared semantic space: robust to paraphrase, but sensitive to language mismatch.
5. Generation and Guard-Rail
Section titled “5. Generation and Guard-Rail”Mistral-7B (temperature 0.1) receives the chunks as context. The prompt is deliberately firm: it instructs the model to use only the context and to refuse out-of-domain questions, reinforced with few-shot examples of the refusal behavior: in-context demonstrations being the prompting mechanism characterized by Brown et al. (2020). Without this firmness, the model would answer questions like “What is the capital of Switzerland?” from its own parametric knowledge (undesirable in a system meant to stay grounded in the corpus).
6. Conversation history
Section titled “6. Conversation history”For multi-turn dialogue, the system keeps the history and injects it into the prompt. Before searching, a condensation step rewrites context-dependent questions (e.g., “does it have moons?” after “tell me about Jupiter”, becomes “does Jupiter have moons?”, improving retrieval performance.
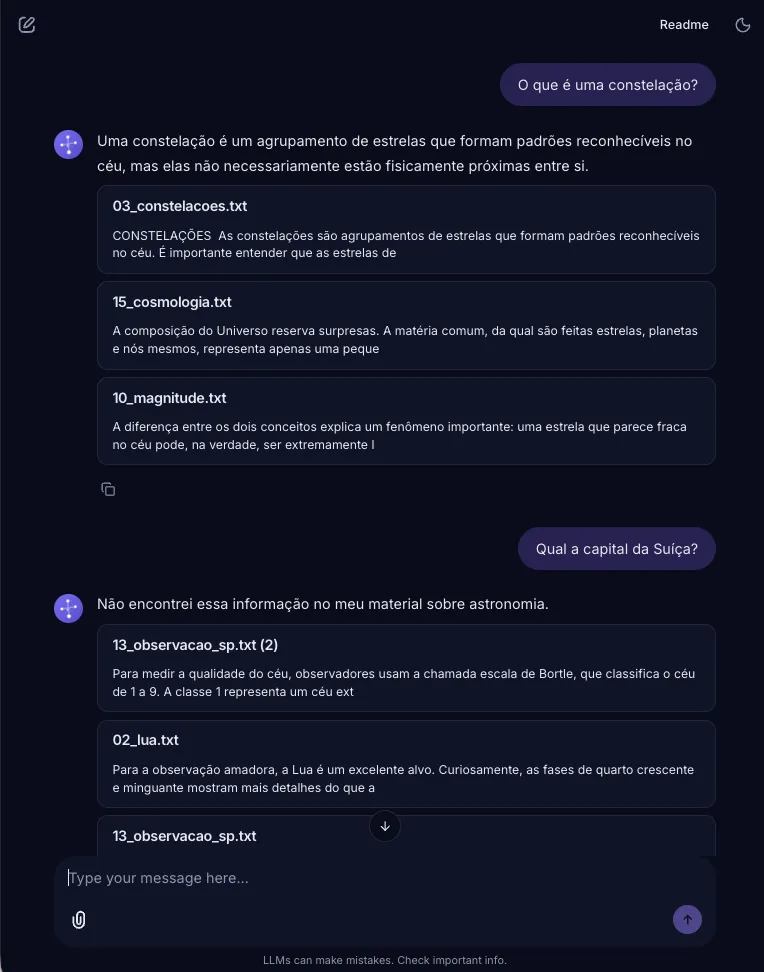
results
Retrieval & answer quality
Section titled “Retrieval & answer quality”Each retriever configuration scored across the golden set. Cells shade against the column max — greener = better, pinker = worse.
| Retriever config | Recall@1 | Recall@3 | Recall@5 | MRR | Subjective / 5 |
|---|---|---|---|---|---|
| dense (k=3) | |||||
| dense + history-aware | |||||
| bm25 baseline | |||||
| no-retrieval (Mistral only) |
Real numbers: Recall@3 = 0.90 and subjective ≈ 3.8/5 (→0.76) are from the project's evaluation report. The other rows are template placeholders — replace the data-v values with your measured results and the shading updates automatically.
Evaluation
Section titled “Evaluation”1. Retrieval
Section titled “1. Retrieval”Recall@3, the fraction of questions where the expected source file appeared among the three retrieved chunks, was 90% (27 out of 30). The three misses had distinct causes:
- “Três Marias” (a Brazilian nickname for Orion’s Belt): the idiomatic expression was poorly represented by the English-trained embedder.
- “Grupo Local” (Local Group): the word “local” matched files about “observing location” (polysemy)
- “What did Galileo discover when he pointed the telescope?”: surface-level word overlap with the telescope file beat the actual intent (history).
2. Generation quality
Section titled “2. Generation quality”Each answer was rated from 1 (failure) to 5 (excellent), yielding a mean of 3.83/5. Most answers are correct and well-grounded; the low scores cluster around undue refusals and one factual error.
3. Failure analysis
Section titled “3. Failure analysis”Reading the answers revealed instructive patterns
Over-refusal and the file vs. Chunk problem
Section titled “Over-refusal and the file vs. Chunk problem”In some cases the model refused even with the correct file retrieved. The cause is granularity subtlety:
Recall@3 is measured at the file level, but retrieval happens at the chunk level. With 86 chunks and top-3, the correct file can appear in the top-3 without the specific chunk containing the answer being retrieved. The model receives context from the right file, but without the exact sentence, and refuses. There is an explicit trade-off: reinforcing the prompt against hallucination raised the rate of undue refusals.
The embedder’s limitation in Portuguese
Section titled “The embedder’s limitation in Portuguese”The three retrieval misses converge on the conclusion that the English-trained embedder is the weakest link when the corpus and questions are in Portuguese, especially for idiomatic expressions and compound technical terms.
Residual knowledge leakage
Section titled “Residual knowledge leakage”In isolated cases the model refused and then answered anyway, occasionally with information not grounded in the context, falling back on parametric knowledge, the very behavior RAG aims to suppress (Lewis et al., 2020). Smaller models tend to be less rigorous about honoring refusing instructions than larger ones.
Engineering decisions and lessons
Section titled “Engineering decisions and lessons”Evaluate before trusting
Section titled “Evaluate before trusting”Without the retrieval metric and a careful reading of the answers, the failure modes (over-refusal, embedder limitation) would have gone unnoticed.
Test retrieval in isolation before generation
Section titled “Test retrieval in isolation before generation”It separates search failures from model failures and saves debugging time
The prompt is a precision lever
Section titled “The prompt is a precision lever”Reinforcing it reduced hallucination but introduced undue refusals, a knob to be calibrated, not maximized.
Next steps: Agentic RAG
Section titled “Next steps: Agentic RAG”The observed failures all point toward evolving from a static RAG to an Agentic RAG, where the system actively decides how to retrieve and when to answer:
- Relevance grading and self-reflection: Having the model assess whether retrieved chunks actually answer the question, and decide whether to retrieve at all, is the core idea of Self-RAG (Asai et al., 2023), which trains a model to emit reflection tokens for this purpose. This directly targets the over-refusal observed here.
- Query rewriting / expansion: reformulating the question before searching, mitigating misses like “Três Marias”.
- Multilingual embedder: replacing
all-MiniLM-L6-v2with a model also trained on Portuguese. - Reasoning-and-acting orchestration: Frameworks like ReAct (Yao et al., 2023) interleave reasoning steps with retrieval actions, turning the reactive pipeline into a planning agent.
References
Section titled “References”-
Asai, A., et al. (2023). Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. arXiv:2310.11511
-
Brown, T., et al. (2020). Language Models are Few-Shot Learners. NeurIPS.
-
Gao, Y., et al. (2023). Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997
-
Jiang, A. Q., et al. (2023). Mistral 7B. arXiv:2310.06825
-
Johnson, J., Douze, M., & Jégou, H. (2019). Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3), 535–547.
-
Karpukhin, V., et al. (2020). Dense Passage Retrieval for Open-Domain Question Answering. EMNLP.
-
Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS. arXiv:2005.11401
-
Oliveira Filho, K. S., & Saraiva, M. F. O. Astronomia e Astrofísica. UFRGS — http://astro.if.ufrgs.br/livro.pdf
-
Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP-IJCNLP.
-
Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS.
-
Yao, S., et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. ICLR. arXiv:2210.03629